为应对新一轮技术竞赛,谷歌还在不断出后手。
这两天,一个名叫PaLM-E的大模型在AI学术圈疯狂刷屏。

它能只需一句话,就让机器人去厨房抽屉里拿薯片。

即便是中途干扰它,它也会坚持执行任务。

PaLM-E拥有5620亿参数,是GPT-3的三倍多,号称史上最大规模视觉语言模型。而它背后的打造团队,正是谷歌和柏林工业大学。
作为一个能处理多模态信息的大模型,它还兼具非常强的逻辑思维。
比如能从一堆图片里,判断出哪个是能滚动的。

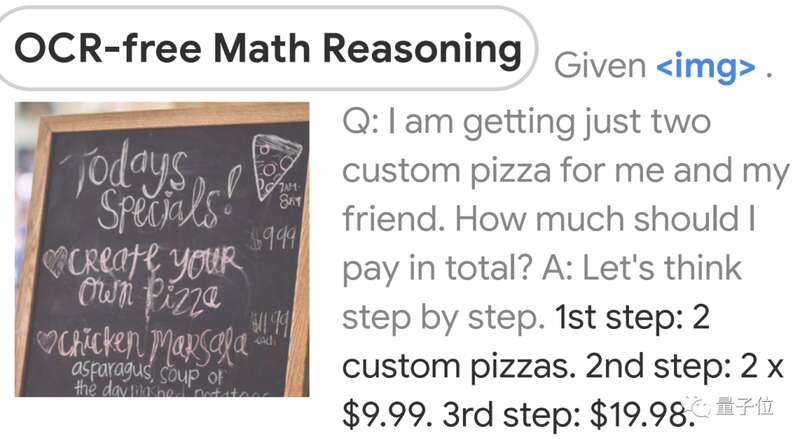
还会看图做算数:
有人感慨:
这项工作比ChatGPT离AGI更近一步啊!

而另一边,微软其实也在尝试ChatGPT指挥机器人干活。
这么看,谷歌是凭借PaLM-E一步到位了?
逻辑性更强的大模型
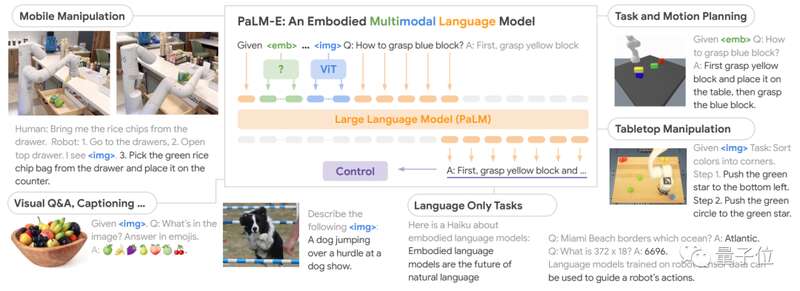
PaLM-E是将PaLM和ViT强强联合。
5620亿的参数量,其实就是如上两个模型参数量相加而来(5400亿+220亿)。
PaLM是谷歌在22年发布的语言大模型,它是Pathways架构训练出来的,能通过“思考过程提示”获得更准确的逻辑推理能力,减少AI生成内容中的错误和胡言乱语。
Pathways是一种稀疏模型架构,是谷歌AI这两年重点发展方向之一,目标就是训练出可执行成千上百种任务的通用模型。
ViT是计算机视觉领域的经典工作了,即Vision Transformer。
两者结合后,PaLM-E可以处理多模态信息。包括:
语言图像场景表征物体表征
通过加一个编码器,模型可以将图像或传感器数据编码为一系列与语言标记大小相同的向量,将此作为输入用于下一个token预测,进行端到端训练。
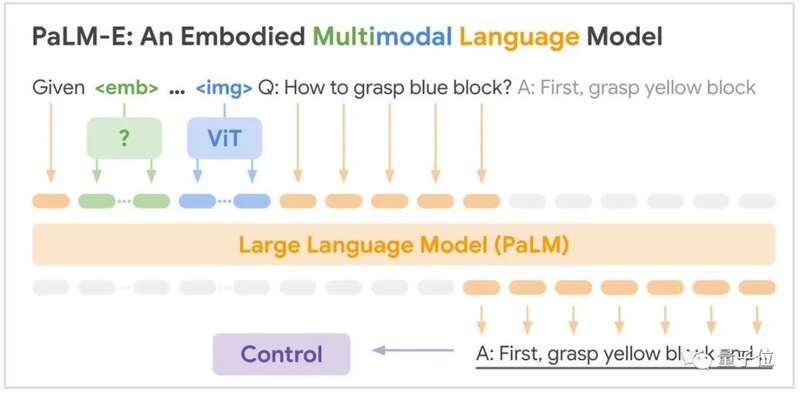
具体能力方面,PaLM-E表现出了比较强的逻辑性。
比如给它一张图片,然后让它根据所看到的做出蛋糕。
模型能先判断出图像中都有什么,然后分成9步讲了该如何制作蛋糕,从最初的磕鸡蛋到最后洗碗都包括在内。
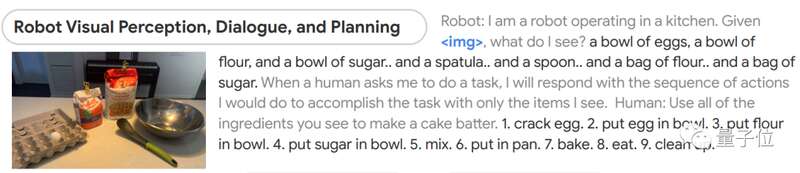
有人还调侃说,这机器人怎么在把蛋糕给我前先自己吃了?

还有根据图片做判断:我能在这条路上骑自行车吗?
模型进行一系列逻辑推断:
1、不能进入
2、除了自行车
3、除了自行车以外都不能进入
4、答案是可以

这和人类思考的过程确实很像了。
不仅如此,模型的最强大之处在于,它无需经过预处理,即提前理解环境。
它做出判断和回答,完全是基于它自己的“经验”。
研究人员表示,这项成果表现出了很强的正向迁移(positive transfer)能力。
在多个领域任务的训练中,PaLM-E的表现都优于单项任务机器人模型。
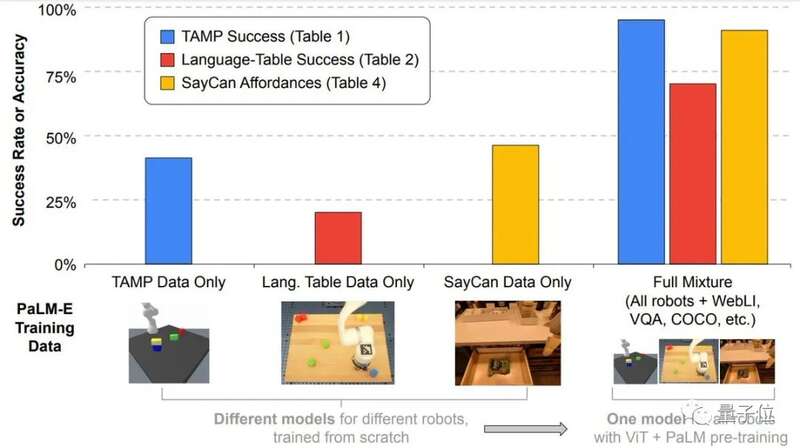
而且他们还发现,语言模型的规模越大,它最终能保持的语言理解能力越强。
比如使用5400亿参数规模的PaLM时,PaLM-E在语言任务上的实际能力仅下降了3.9%。

从实验结果来看,PaLM-E在OK-VQA基准上达到新SOTA。

在模拟环境下的任务完成度也都不错。

再次验证大力出奇迹
目前这项研究已引发非常广泛的讨论。
主要在于以下几个方面:
1、一定程度上验证了“大力出奇迹”
2、比ChatGPT更接近AGI?
一方面,作为目前已知的规模最大的视觉语言模型,PaLM-E的表现已经足够惊艳了。
去年,DeepMind也发布过一个通才大模型Gota,在604个不同的任务上接受了训练。
但当时有很多人认为它并不算真正意义上的通用,因为研究无法证明模型在不同任务之间发生了正向迁移。
论文作者表示,这或许是因为模型规模还不够大。
如今,PaLM-E似乎完成了这一论证。

不过也有声音担心,这是不是把卷参数从NLP引到了CV圈?

另一方面,是从大趋势上来看。
有人表示,这项工作看上去要比ChatGPT更接近AGI啊。
的确,用ChatGPT还只是提供文字建议,很多具体动手的事还要自己来。
但PaLM-E属于把大模型能力拉入到具象化层面,AI和物理世界之间的结界要被打破了。

而且这个趋势显然也是大家都在琢磨的,微软前不久也发布了一项非常相似的工作——让ChatGPT指挥机器人。
除此之外,还有很多人表示,这再一次验证了多模态是未来。
不过,这项成果现在只有论文和demo发布,真正能力有待验证。
此外还有人发现,模型驱动的机器人,背后的开发团队在几周前被谷歌一锅端了。。。
所以关于PaLM-E的更多后续,咱们还得再蹲蹲看。